When you develop software to work with PDF files, you often need to be able to drill down into a file and see the internal structure. The PDF file format is a complex ascii/binary format and you cannot just view it in an editor. You need a tool which can understand the file structure and show the raw data.
RUPS
RUPS is a free tool from the iText development team which allows you to open PDF files and see the actual object data. It has a really nice GUI front end and allows you to drill down into the objects. If you are developing software to use PDF files (or need to understand what is in your PDF files), it will save you a lot of time!
You can find out more and download the software from the RUPS home page
Here is an example PDF file.
And this is what it looks like in RUPS! I am looking at the XObject which is the main image on the page. As you can see there are a wide range of tabs allowing you to view the PDF objects in different ways. You can see the image displayed in the bottom right corner and all the Dictionary information on the left.
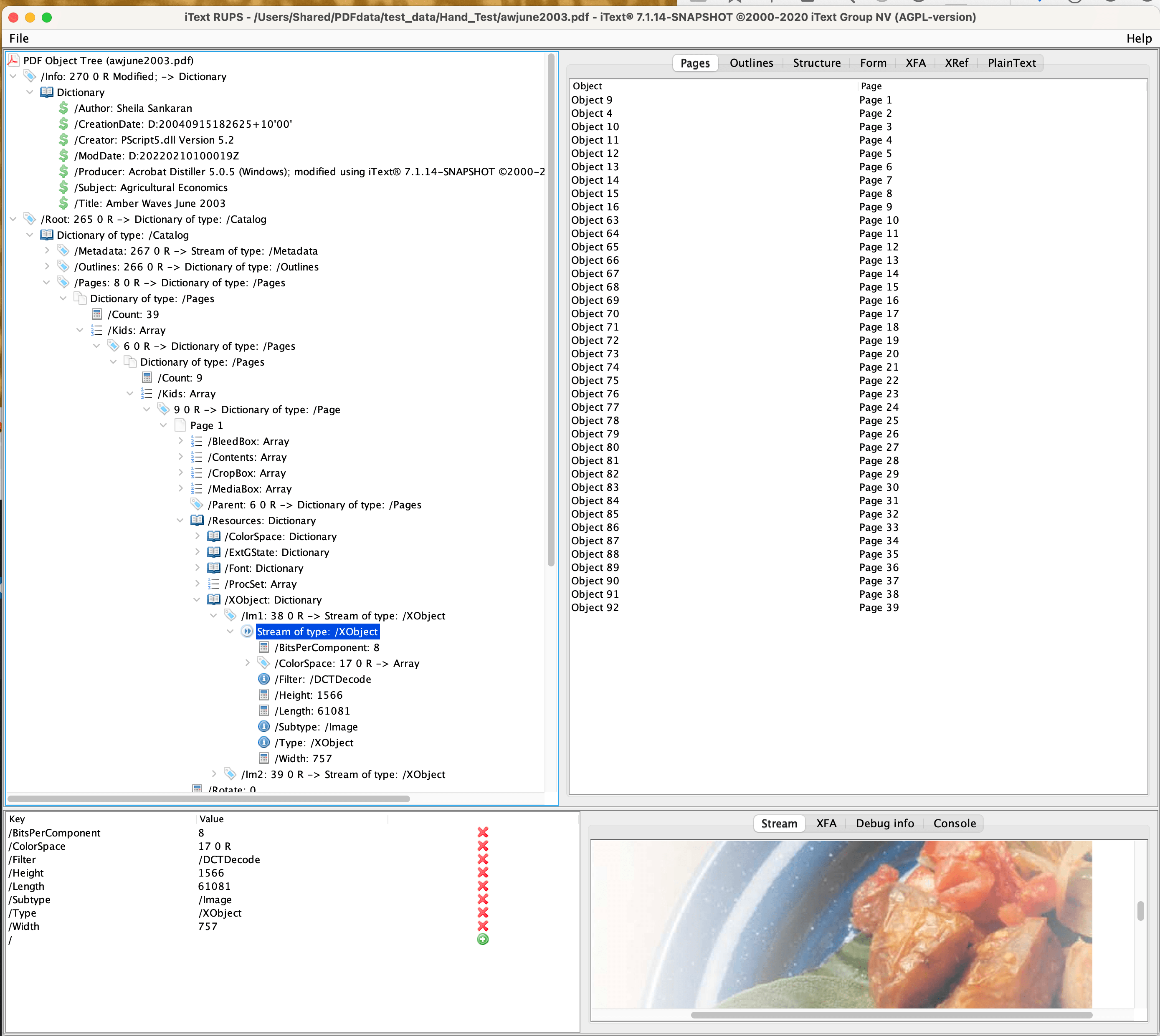
In this case, you could access this data directly in the file, but it would be a lot less clear and you would not see the file structure.
JPedal Viewer
Our own JPedal Viewer now has a mode to inspect PDF files. And it works in both the trial and the full versions (so you do not need to be a customer to use it).
It also has a unique feature to allow you to see and debug the PDF content streams.
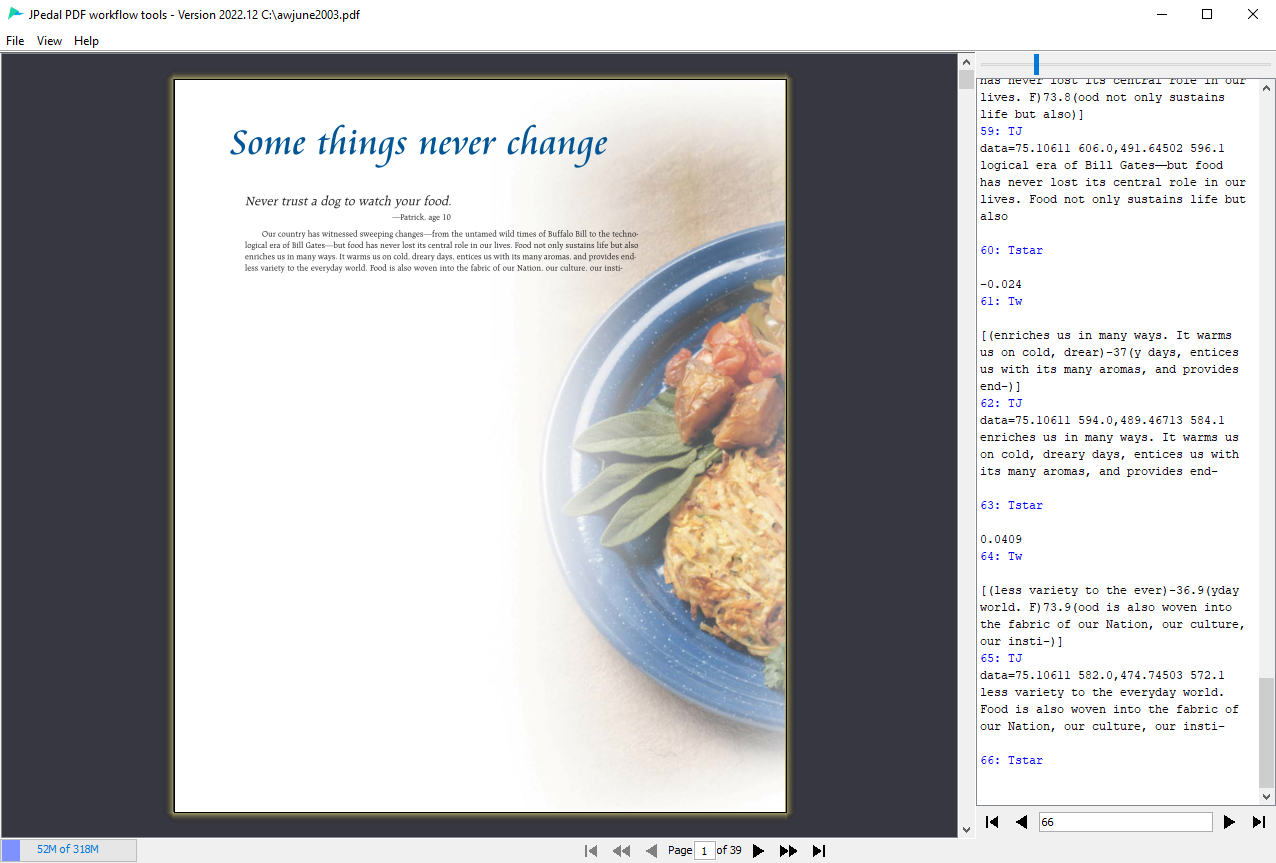
You can find out more and download the software from the support page
PDFXplorer
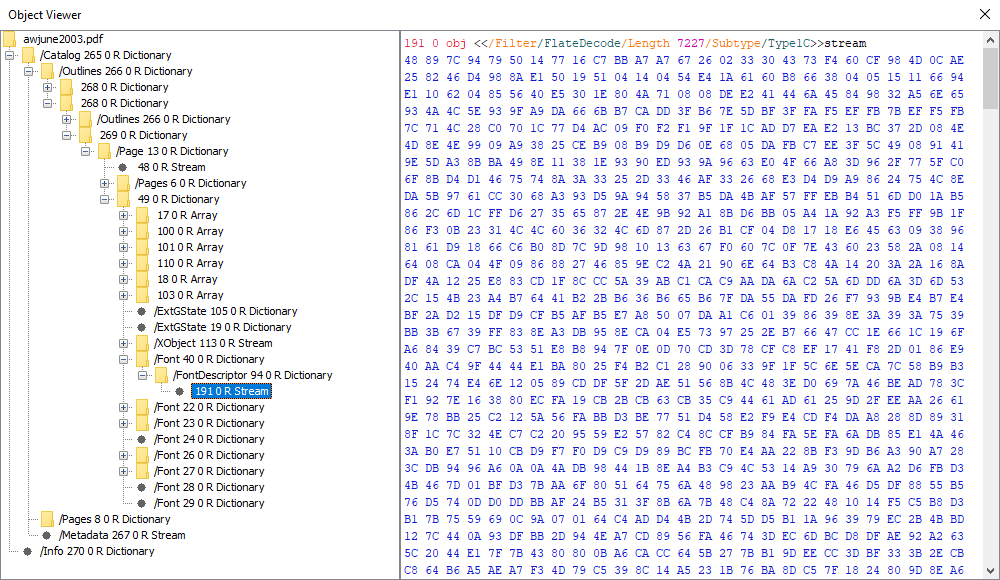
PDFXplorer is a another free tool from O2 Solutions. It is a small, Windows only, freeware application that allows you to explore the internal structure of a PDF as it is laid out in a tree. Turning this:

To this:

It lists each of the objects attributes in a neatly laid out table, has a good navigation tab that lets you easily move about the PDF, and also allows you to view and save streams and text data within the PDF file.
This can be very useful for example it comes in very handy when you want to know what embedded JavaScript is present within the PDF and what object it is associated with. Or to extract certain kinds of images from the PDF.
What does all this data mean?
If you would like to better understand this data and what is going on inside a PDF file, you might find our other blog post on Learning about PDF helpful.
Our software libraries allow you to
| Convert PDF files to HTML |
| Use PDF Forms in a web browser |
| Convert PDF Documents to an image |
| Work with PDF Documents in Java |
| Read and write HEIC and other Image formats in Java |