Today marks a brand new release of JPedal and with it comes some exciting new features including a PDF inspector! JPedal is the best Java PDF library for developers.
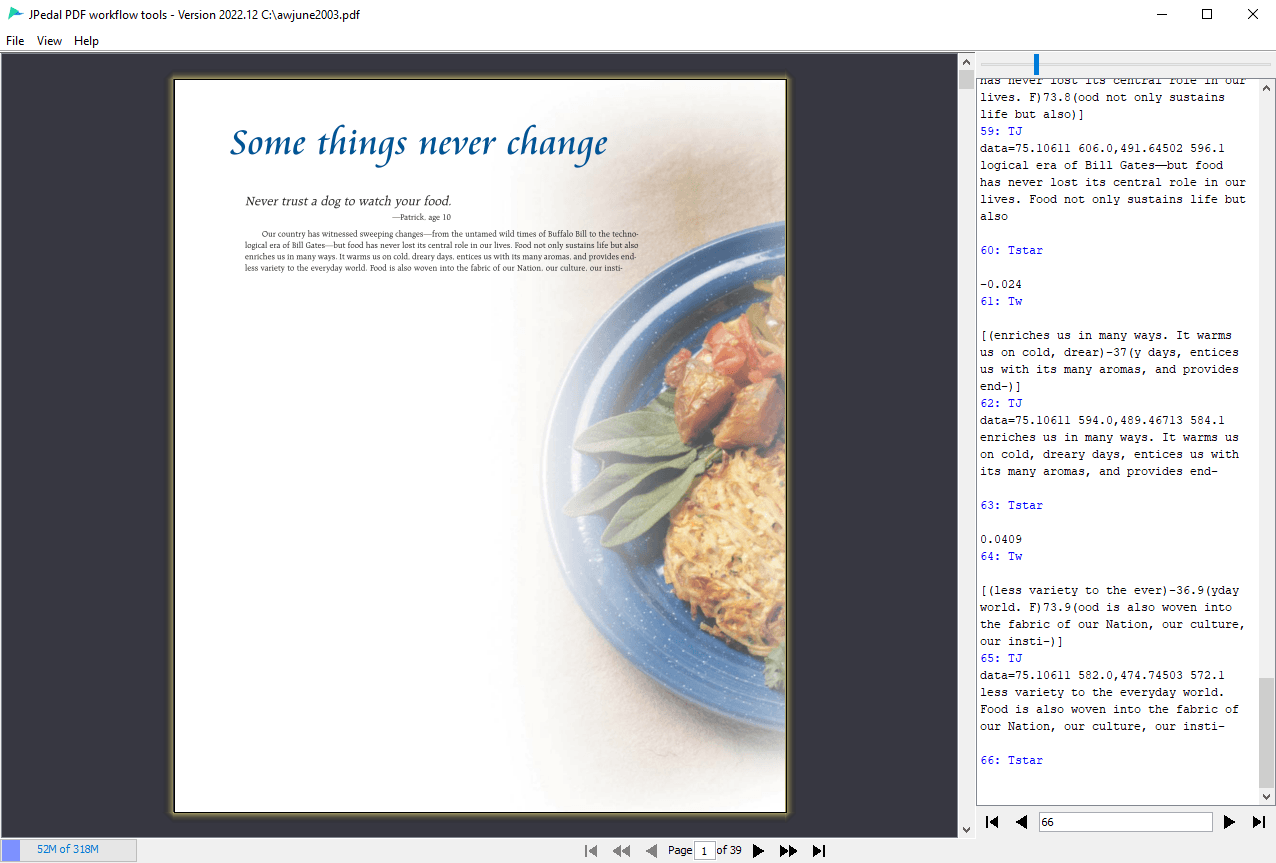
Limit Decode Slider
The Limit Decode Slider allows you to pause the decoding of a PDF file at a given command. You can then increment through commands to see precisely how the PDF file is drawn. The right-hand pane displays each command in blue and its associated data above it in black. TJ commands also output their resolved text directly below themselves.
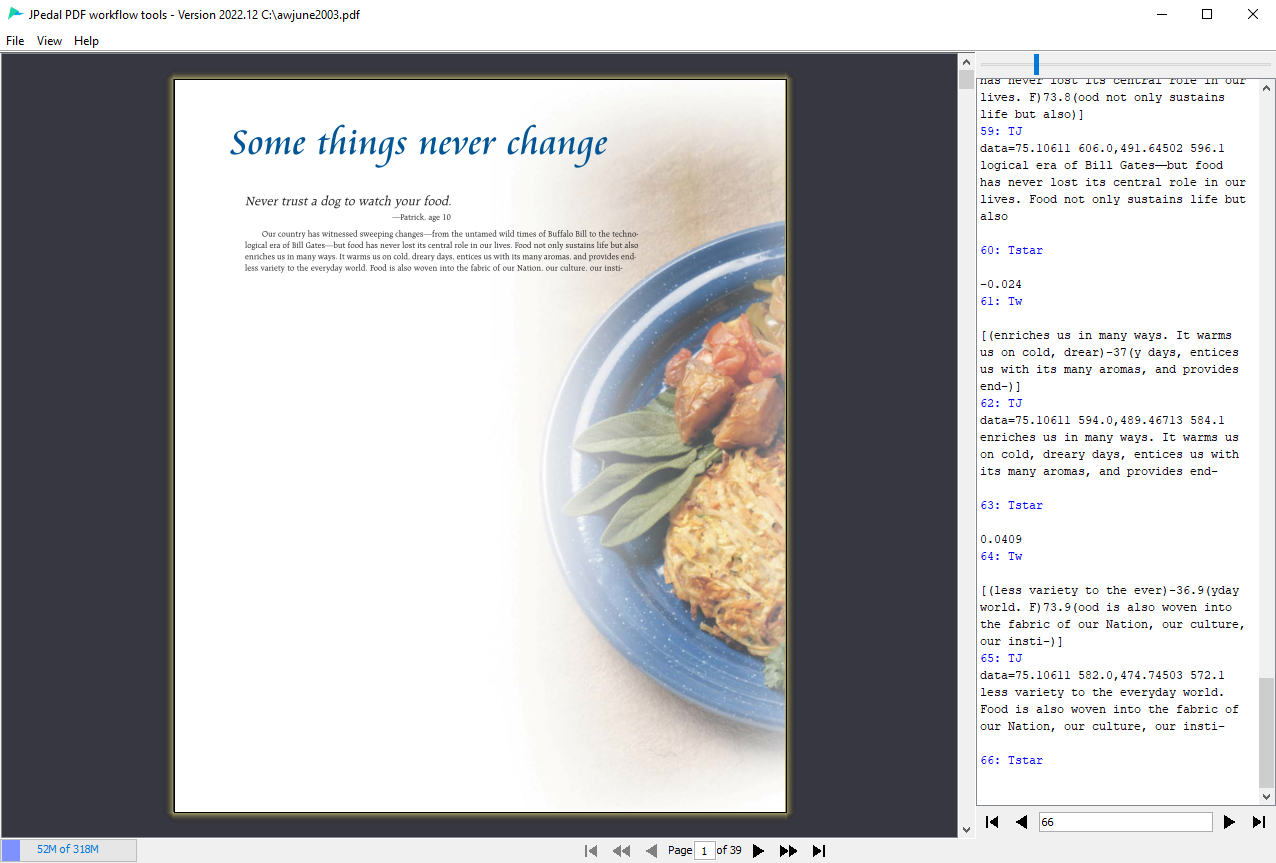
Object Viewer
The Object Viewer allows you to see the internal tree structure of a PDF file and how all the objects are related to one another. Each node in the tree contains the object’s reference, its type (i.e. dictionary, stream, array), and if it has one, its /Type key (i.e. /XObject). You may click on an object to view its contents in the right-hand pane.
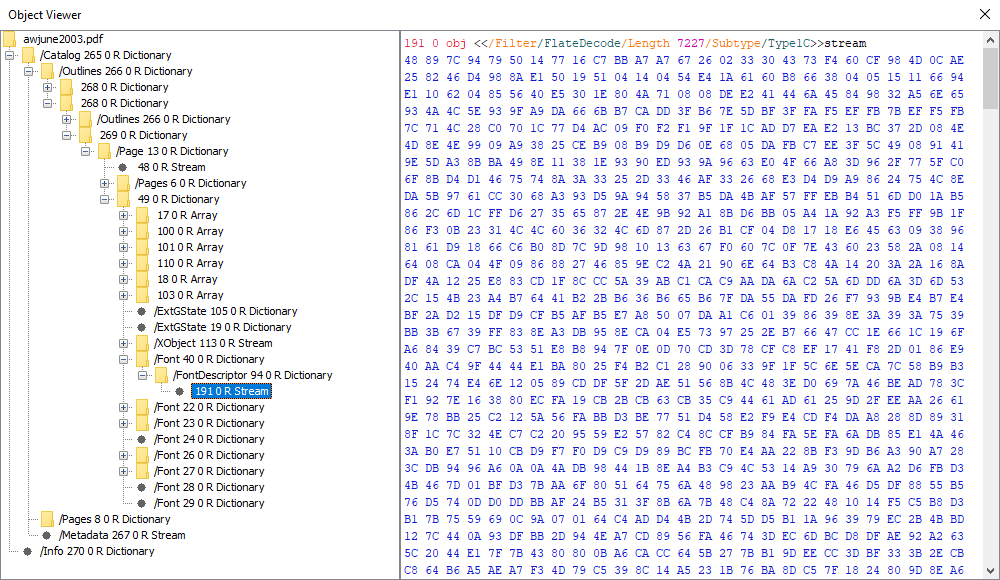
Object Highlighting
The Object and Xref Viewers now highlight the tokens in objects. Below is a list of colors and what they mean.
| Object | Color |
| Dictionary Key | Orange |
| Dictionary Value | Cyan |
| Object Reference | Red |
| Number | Purple |
| Boolean | Green |
| String | Blue |
| Hexadecimal | Blue |
The most recent version of the colors is available here.
Learn more
You can read more about the JPedal’s PDF Inspector on our support site.
The JPedal PDF library allows you to solve these problems in Java
//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
final PdfManipulator pdf = new PdfManipulator();
pdf.loadDocument(new File("inputFile.pdf"));
pdf.addPage(1, PaperSize.A4_LANDSCAPE);
pdf.addText(1, "Hello World", 10, 10, BaseFont.HelveticaBold, 12, 1, 0.3f, 0.2f);
pdf.addImage(1, new BufferedImage(), new float[] {0, 0, 100, 100});
pdf.rotatePage(1, 90);
pdf.apply();
pdf.writeDocument(new File("outputFile.pdf"));Viewer viewer = new Viewer();
viewer.setupViewer();
viewer.executeCommand(ViewerCommands.OPENFILE, "pdfFile.pdf");
//Convenience static method (see class for additional options)
ExtractTextAsWordList.writeAllWordlistsToDir("inputFileOrDirectory", "outputDir", -1);
PdfMerge.mergeFiles(new File("inputFile1.pdf"), new File("inputFile2.pdf"), new File("outputFile.pdf"));
PdfManipulator.splitInHalf(new File("inputFile.pdf"), new File("outputFolder"), pageToSplitAt);PrintPdfPages print = new PrintPdfPages("C:/pdfs/mypdf.pdf");
if (print.openPDFFile()) {
print.printAllPages("Printer Name");
}//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
//Convenience static method (see class for additional options)
ArrayList resultsForPages = FindTextInRectangle.findTextOnAllPages("/path/to/file.pdf", "textToFind");
java -jar jpedal.jar --inspect "inputFile.pdf"PdfSigner.signPdf(
"inputFile.pdf",
"outputFile.pdf",
"keystorePassword",
"keystoreFile.p12",
"signerName",
"signerLocation",
"signingReason",
ACCESS_PERMISSION.P1
);What is JPedal?
JPedal is a commercial Java PDF Library that makes it easy for Java developers to work with PDF Documents in Java.
Why use JPedal?
JPedal makes it much easier to work with PDF files from Java. Because we have been actively developing our Java PDF Toolkit for over 20 years, it works with all those problem PDF files out there.
What licenses are available?
We have 2 licenses available:
'Server' for on premises and cloud servers and 'OEM' for use in a named end user applications. Both are one time fees with options support renewal after 12 months.
How to use JPedal?
Want to learn more about JPedal and how to use it, we have plenty of tutorials and guides to help you.