
Early Text Storage
In the early days of computers, text was stored in a simple way. Usually, one byte was used per character giving you the ability to use up to 128 different characters.
(Back then the number of bits in a byte was not universally agreed, so the smallest regularly used byte length – 7 bits – was used.) Different computer systems would come up with a different set of characters (and control characters) which suited their needs.
The Introduction of ASCII
Soon, people started needing to move text between different systems. In 1968, US President Lyndon B. Johnson announced that the federal government would only use computers which supported ASCII – an earlier encoding designed primarily for use on teleprinters.
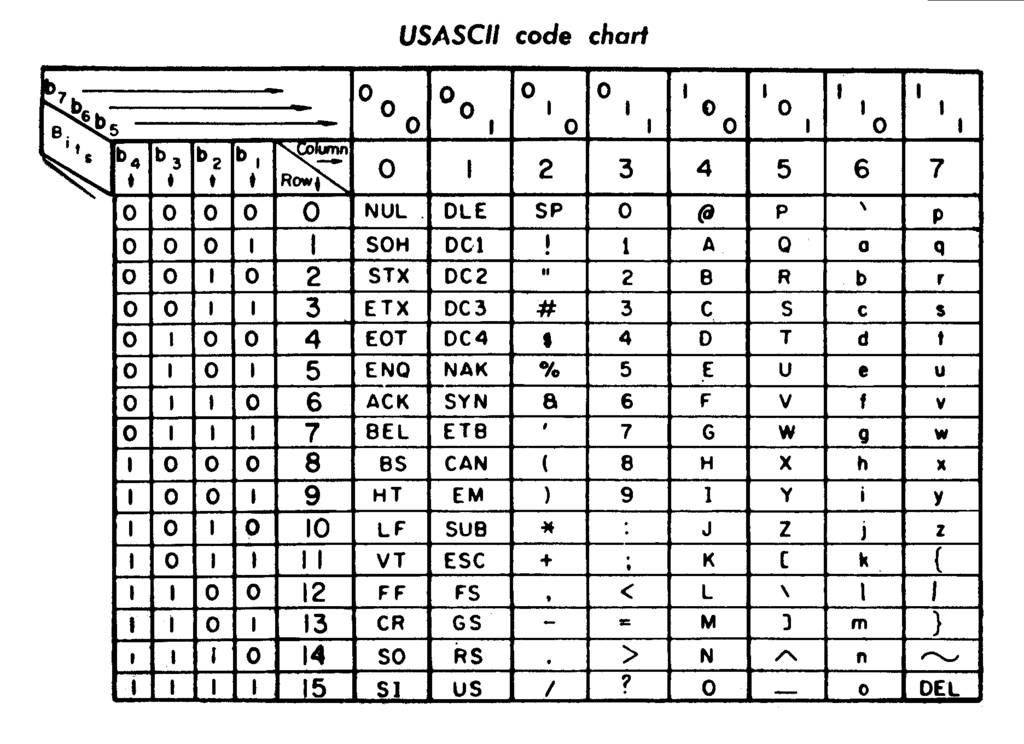
ASCII’s Global Limitations
ASCII turned out not to be the best solution, but it had a lasting impact – everything you’ve read so far in this article is effectively written in ASCII.
The first major problem encountered with ASCII is when it was used outside of the US. Here in the UK, an obvious problem appeared – there was no ‘£’ character. As a result, the UK made it’s own variation of ASCII.
Then France tried it out, and realized there was no ‘à’, ‘ç’, ‘é’ and so on, so they made their own version of ASCII. Soon, there were dozens of different versions of ASCII used in different parts of the world.
Of course, ASCII was almost completely useless in countries which use non-latin alphabets. Unfortunately, vital internet infrastructure like email protocols were only designed to deal with 7 bit character encoding, meaning only very restricted versions of languages like Japanese (which has around 50,000 characters!) could be used.
The Birth of Unicode
The answer to these two problems at first seemed simple – use more bits and encode every character in use today. And thus, in 1991, Unicode was born.
Unicode started as a 16 bit character encoding, allowing it to encode 65,536 characters. All currently used characters worldwide except for the rarest Chinese characters were encoded.
As a bonus, to ensure backwards compatibility in the west, the first 128 characters are identical to ASCII.
Unicode Expansion and Evolution
But of course, as with all which came before it, Unicode proved to not have enough space for what everyone wanted to do with it – this time only 5 years after it’s initial release.
However, instead of being replaced, Unicode evolved. Unicode now refers to a range of different encodings which all map onto the Universal Character Set – a list of characters along with a unique name and a unique integer called it’s code point.
The Universal Character Set
The Universal Character Set originally contained only the 65,536 characters available within Unicode, but has now grown to contain over 110,000 characters, including everything from Ancient Egyptian to Emoji.
Encoding, however, remained a concern. The number of bits required for text had already raised from 7, to 8, to 16 over the years. As a result, variable length Unicode encodings like UTF-8 – the most common encoding on the internet – emerged.
Most regular English text will require one byte per character, and up to 3 more bytes are used if required. Formulas allow these variable length codes to map onto any of the 1 million+ code points in Unicode.
Unicode covers much more than just encoding, including a rules and algorithms for displaying and transforming text, but I hope this has given you a good starting point.
Our software libraries allow you to
| Convert PDF files to HTML |
| Use PDF Forms in a web browser |
| Convert PDF Documents to an image |
| Work with PDF Documents in Java |
| Read and write HEIC and other Image formats in Java |