

How are images stored in a PDF file?
When I was learning the PDF file format, I found Images could be quite a complex topic in PDF so I wrote this article to hopefully explain them clearly. Please do let me know if you have any suggestions to improve it or it raises any questions for you.
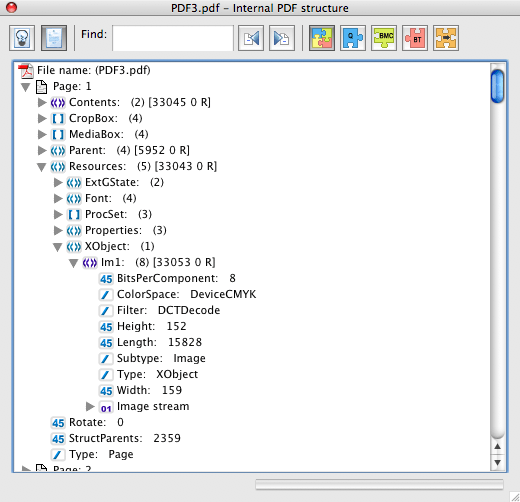
A PDF file usually stores an image as a separate object (an XObject) which contains the raw binary data for the image. These are all listed in the Resources object for the page or the file and each has a name (ie Im1). It is wrong to think of images embedded inside a PDF as Tif, Gif, Bmp, Jpeg or Png. They are not.
It is important to appreciate that this is not usually an image in the sense of a Tif or a Jpg or a Png image – it is the binary data for the pixels, the colorspace used for the image, information about the Image. The image is ripped apart when the PDF is created and different PDF creation tools may store the same image in very different ways.
Here is an example shown in the PDF object viewer in Acrobat.

Sometimes the raw image data is adjusted to the required size needed for the page and sometimes it is not – in that case it is scaled up or down when it is drawn – different PDF creation tools create PDF files in very different ways.
The actual pixel data can be compressed and one of the compression formats (DCTDecode) is the same used as in a JPEG (JPX is the same as Jpeg2000). If you save this data, it can be opened as a JPEG file, but it may need altering to include the colorspace data.
This image is then drawn in the PDF contents stream by a DO command and the image name (ie Im1). The image can be used multiple times and scaled, rotated or clipped – it takes whatever vales are set when the DO command is executed. Some things which appear as an image to the eye may also be made up of multiple images or not even images at all!
All this means that if you want to extract images from a PDF, you need to assemble the image from all the raw data – it is not stored as a complete image file you can just rip out.
And also there is a ‘raw’ (which is sometimes a much higher quality and sometimes exactly the same size) version of the image and a clipped/scaled version of the image – both can be extracted (and you can also scale the clip up onto the raw to produce a higher quality image – we make use of this in JPedal to provide PDF Clipped Image Extraction).
As with everything PDF, there is a lot of flexibility and lots of alternatives and options…