How are images stored in a PDF file?
When I was learning the PDF file format, I found Images could be quite a complex topic in PDF so I wrote this article to hopefully explain them clearly. Please do let me know if you have any suggestions to improve it or it raises any questions for you.
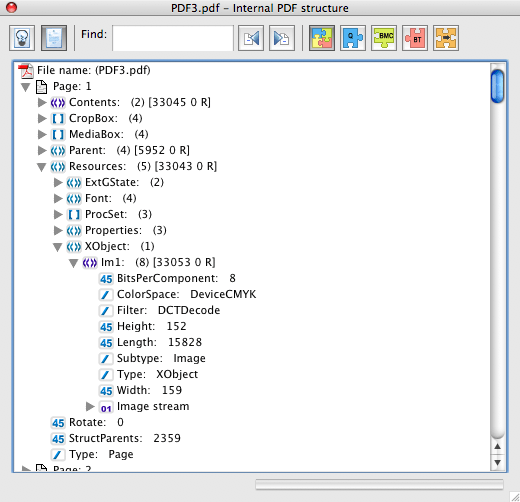
A PDF file usually stores an image as a separate object (an XObject) which contains the raw binary data for the image. These are all listed in the Resources object for the page or the file and each has a name (ie Im1). It is wrong to think of images embedded inside a PDF as Tif, Gif, Bmp, Jpeg or Png. They are not.
It is important to appreciate that this is not usually an image in the sense of a Tif or a Jpg or a Png image – it is the binary data for the pixels, the colorspace used for the image, information about the Image. The image is ripped apart when the PDF is created and different PDF creation tools may store the same image in very different ways.
Here is an example shown in the PDF object viewer in Acrobat.

Sometimes the raw image data is adjusted to the required size needed for the page and sometimes it is not – in that case it is scaled up or down when it is drawn – different PDF creation tools create PDF files in very different ways.
The actual pixel data can be compressed and one of the compression formats (DCTDecode) is the same used as in a JPEG (JPX is the same as Jpeg2000). If you save this data, it can be opened as a JPEG file, but it may need altering to include the colorspace data.
This image is then drawn in the PDF contents stream by a DO command and the image name (ie Im1). The image can be used multiple times and scaled, rotated or clipped – it takes whatever vales are set when the DO command is executed. Some things which appear as an image to the eye may also be made up of multiple images or not even images at all!
All this means that if you want to extract images from a PDF, you need to assemble the image from all the raw data – it is not stored as a complete image file you can just rip out.
And also there is a ‘raw’ (which is sometimes a much higher quality and sometimes exactly the same size) version of the image and a clipped/scaled version of the image – both can be extracted (and you can also scale the clip up onto the raw to produce a higher quality image – we make use of this in JPedal to provide PDF Clipped Image Extraction).
As with everything PDF, there is a lot of flexibility and lots of alternatives and options…
Our software libraries allow you to
| Convert PDF files to HTML |
| Use PDF Forms in a web browser |
| Convert PDF Documents to an image |
| Work with PDF Documents in Java |
| Read and write HEIC and other Image formats in Java |
Extraction would be cool but first of all it seems impossible to be able to tell if an image actually EXISTS within a pdf. Using Apache Tika, I am able to extract pdf content but only the text gets extracted as content. Do you know a way in which to determine if an image exists in a PDF ?
Thanks.
You would need to scan all the Resources objects (and any Resources Objects on Xforms) so see if they contain any image objects and also scan all the streams for inline images.
Thank you so much! Up until I read this post, I thought the images inside a PDF were either PNG or JPEG and was so confused when I couldn’t find PNG or JPEG signatures inside the PDFs.
This was so informative.. Thanks for this post:)
THANK YOU , ITS VERY HELPFULL
So is there a way to extract images from PDFs without de-compresing and re-compressing them?
Most images do not exist as actual images – they are raw data which needs to be put together with a ColorSpace or other data. Several tools can do this for you. The examples for JPedal are at https://www.idrsolutions.com/docs/jpedal/tutorials/extract-images/extract-images-from-pdf
This was very helpful. I also didn’t know about the images being stored as a separate object and have been working with PDFs (editing, creating, printing) for many years. Im assuming so, but does that also include if you have a group of tif & jpeg images and you combine them into a pdf? A common occurrence in our world is our customers requesting printing of PDFs and then we have to break out the pricing between black & white vs. color images. Is there another way to parse those out? Other than sitting down and scrolling through all the PDFs? We are using Adobe Acrobat Pro X. Thank you for this information I am passing it along to my team.
The Image data is stored separately from the colour data. You can compress the image data using CCITT (Tiff) and DCT/JPX (JPEG/JPEG2000) format but this is not the same as them being actual images. In some cases (ie DeviceRGB colorSpace) they can be equivalent to final image but they cannot really be treated as self-contained images.
Thank You so much! Very helpful to understand how PDF works.
But i didn´t find in any place how to use a image inside a PDF as monochrome.
I’m with a problem where my PDF has a barcode image, the printers are identifying my PDF as colored, but it isn´t.
Do you know how can i convert that to Monochrome or exist a way to force my entire PDF as monochrome?
It may well be stored as coloured data even if it looks black and white. Some print drivers will allow you to print as monchrome. You could use a tool like IText to edit the PDF data or a tool like JPedal to extract the image and make black and white.
I received some pdf files from a public disclosure request.
They are of two types:
1) Content Creator / Encoding Software: Xerox Color C70
2) Content Creator / Encoding Software Adobe Acrobat Pro 9.0.0
I have converted both to RTF format using Adobe Pro DC on a 2019 iMac.
However, I believe #2 converted better. AND, in the #2 converted RTF
files I am finding text not found in the original PDF files.
Could anyone suggest how I might get some help with this?
HI,
I’m removing some images from PDF, but sometimes the whole page comes as an image. I can understand if the pages were scanned in as images. However, in many of these PDF’s I can copy and paste the text out of the pages. So I was surprised the pages came out as images, not just the “pictures”.
Can you explain this, that is , copy and paste text, but pages come out as images?
My guess would be the page is OCRed so you have both the picture and the text drawn on the page. The PDF is whatever the PDF creation tool adds, so pages can be just images or a mix.
PDFs can contain complete JPEG files. Any XObject using the DCTDecode filter should be a complete JPG stream that can be extracted to a JPG file and opened like any other image. However, it may be additionally compressed with Flate or another filter inside the PDF.