

As someone who works with PDFs, it is not straightforward to view PDF metadata since it is not directly supported by Java. This tutorial shows you how to check and extract metadata from a PDF file in simple steps using the JPedal Java PDF library.
How to find a PDF file page count
- Add JPedal to your class or module path. (download the trial jar).
- Create a File handle, InputStream or URL pointing to the PDF file
- Include a password if file password protected
- Open the PDF file
- Read the page count
- Close the PDF file
and the Java code to get a page count…
PdfUtilities extract=new PdfUtilities("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
int pageCount=extract.getPageCount();
}
extract.closePDFfile();
You can try print out the result to see if it’s working:
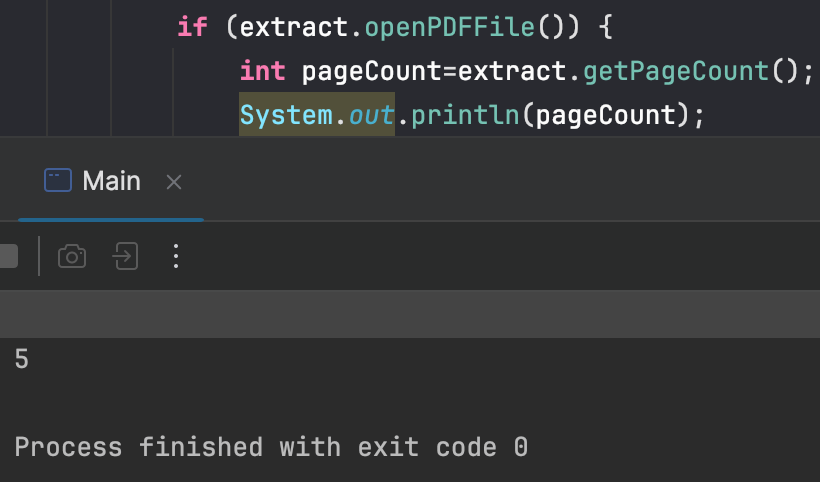
How to access a PDF file page size and rotation
- Add JPedal to your class or module path. (download the trial jar).
- Create a File handle, InputStream or URL pointing to the PDF file
- Include a password if file password protected
- Open the PDF file
- Read the page size and rotation
- Close the PDF file
and the Java code to read PDF page size and rotation…
PdfUtilities extract=new PdfUtilities("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
float[] pageDimensions = extract.getPageDimensions(pageNum, PageUnits.Inches,
PageSizeType.CropBox););
}
extract.closePDFfile();
You can try print out the result to see if it’s working: (getPageDimensions returns a float[] with 5 values:- x,y,w,h, pageRotation)
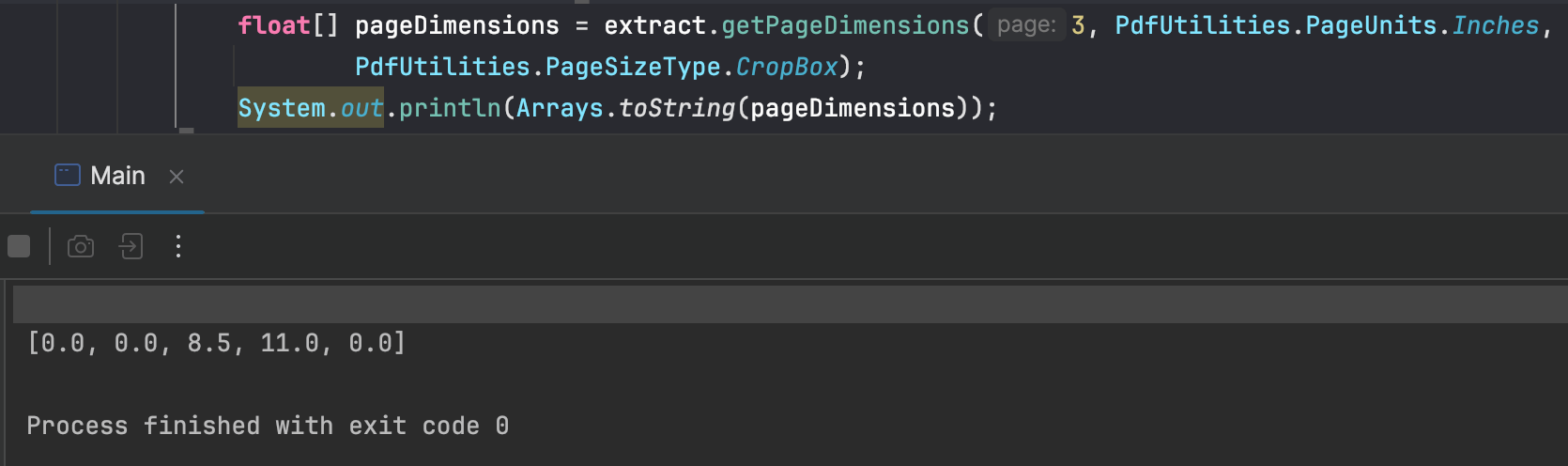
How to access PDF Document properties
- Add JPedal to your class or module path. (download the trial jar).
- Create a File handle, InputStream or URL pointing to the PDF file
- Include a password if file password protected
- Open the PDF file
- Access the properties
- Close the PDF file
and the Java code to read PDF Document properties…
PdfUtilities extract=new PdfUtilities("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
Map mapOfValuePairs=extract.getDocumentPropertyStringValuesAsMap();
String XMLStringData=extract.getDocumentPropertyFieldsInXML();
}
extract.closePDFfile();
You can try print out the result to see if it’s working:
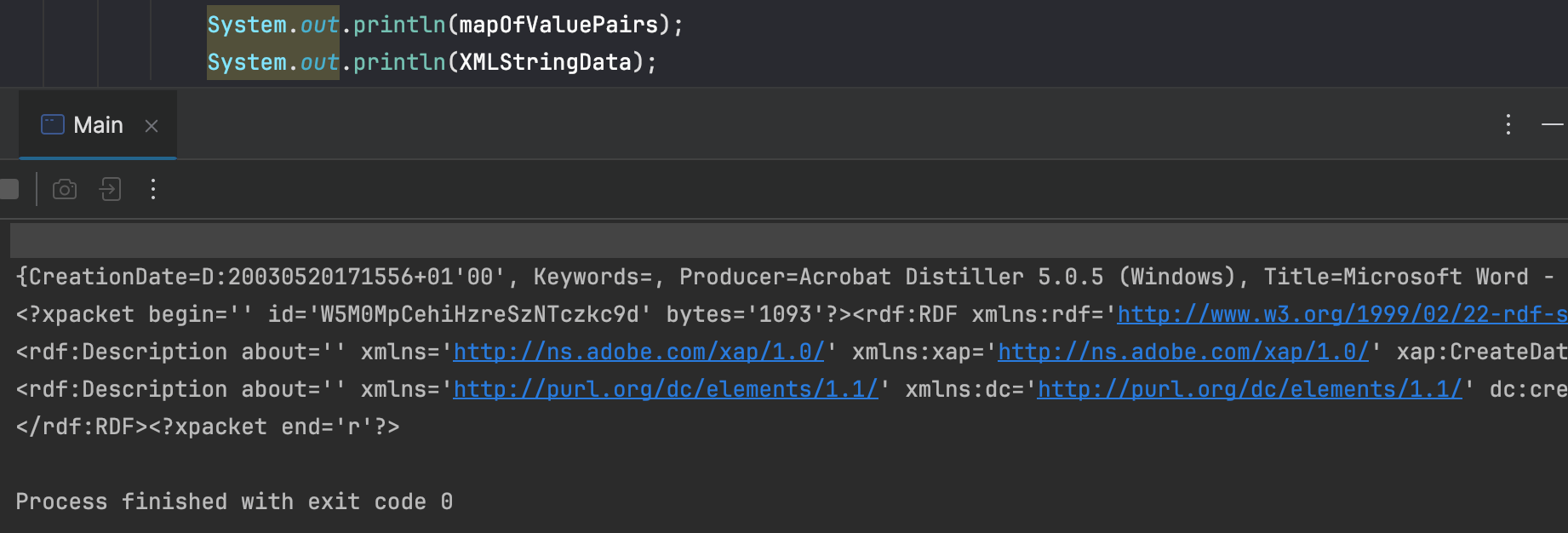
How to detect if embedded fonts used in PDF
- Add JPedal to your class or module path. (download the trial jar).
- Create a File handle, InputStream or URL pointing to the PDF file
- Include a password if file password protected
- Open the PDF file
- Query the PDF file status
- Close the PDF file
and the Java code to detect embedded fonts…
PdfUtilities extract=new PdfUtilities("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
boolean usesEmbeddedFonts=extract.hasEmbeddedFonts();
}
extract.closePDFfile();
Again, you can try print out the result to see if it’s working:
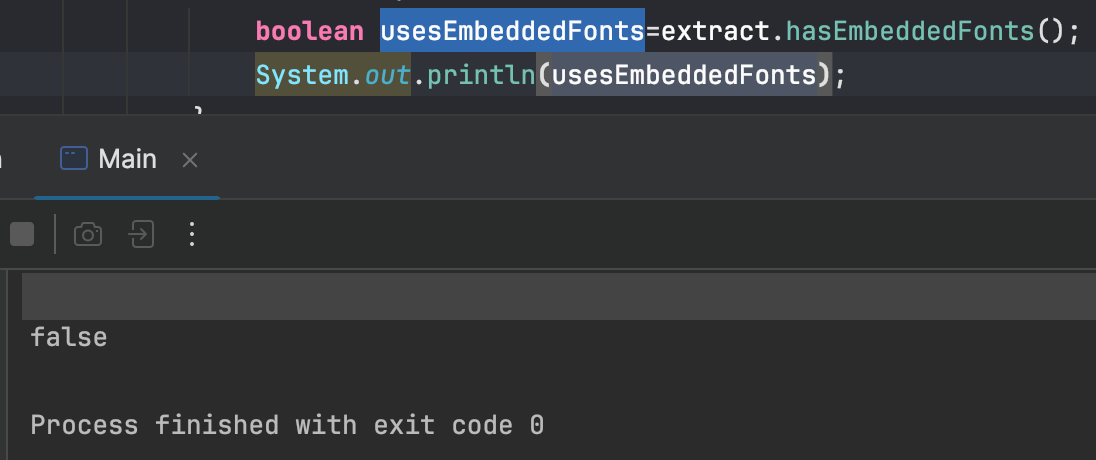
In this article I showed you how you can view pdf metadata using Java.
The JPedal PDF library allows you to solve these problems in Java
Viewer viewer = new Viewer();
viewer.setupViewer();
viewer.executeCommand(ViewerCommands.OPENFILE, "pdfFile.pdf");
//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
//Convenience static method (see class for additional options)
ExtractTextAsWordList.writeAllWordlistsToDir("inputFileOrDirectory", "outputDir", -1);
//Convenience static method (see class for additional options)
ArrayList resultsForPages = FindTextInRectangle.findTextOnAllPages("/path/to/file.pdf", "textToFind");
PrintPdfPages print = new PrintPdfPages("C:/pdfs/mypdf.pdf");
if (print.openPDFFile()) {
print.printAllPages("Printer Name");
}//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
Why do developers choose JPedal over alternatives?
- Actively developed commercial library with full support and no third party dependencies.
- Simple licensing options and source code access for OEM users.
- Process PDF files up to 3x faster than alternative Java PDF libraries.