A PDF document structure consists of several components that determines how text, images and other elements are stored and displayed. It is a binary file format which means you cannot easily edit PDF files in a text editor. Adding or removing even a single character can break the entire file!
Structure of a PDF file
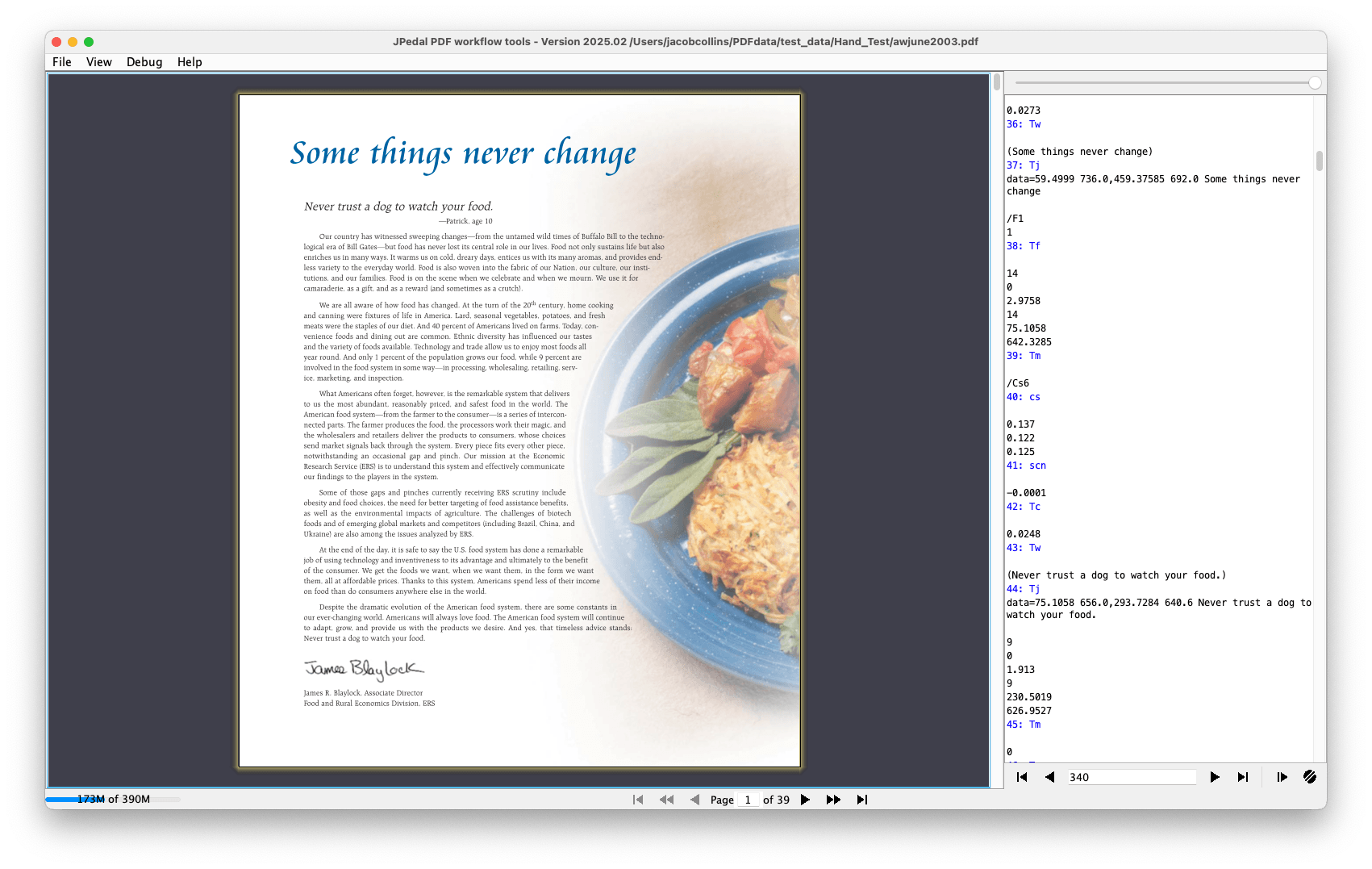
Understanding the PDF document structure is essential for developers working with these files. Internally, a PDF file contains a header, body, cross-reference table, and trailer.
Header
The start of a PDF file contains the following bytes which indicate which version of the PDF specification the file conforms to.%PDF-2.0
Body
The body of a PDF file consists of a series of PDF object types which dictate the appearance and contents of the file. There are nine types of objects including:
- Boolean objects
- Number objects
- Real (floating point) objects
- Integer objects
- String objects
- Name objects
- Array objects
- Dictionary objects
- Stream objects
- The null object
Objects are linked together in a tree structure. The /Root object comes first, it will have a child object called /Pages which contains the pages for the file. Each page will then have a /Contents stream object containing drawing instructions for how to render the page and a /Resources dictionary object which contains things required by the contents stream, such as images or color settings. In newer PDFs, objects may also be compressed in streams.
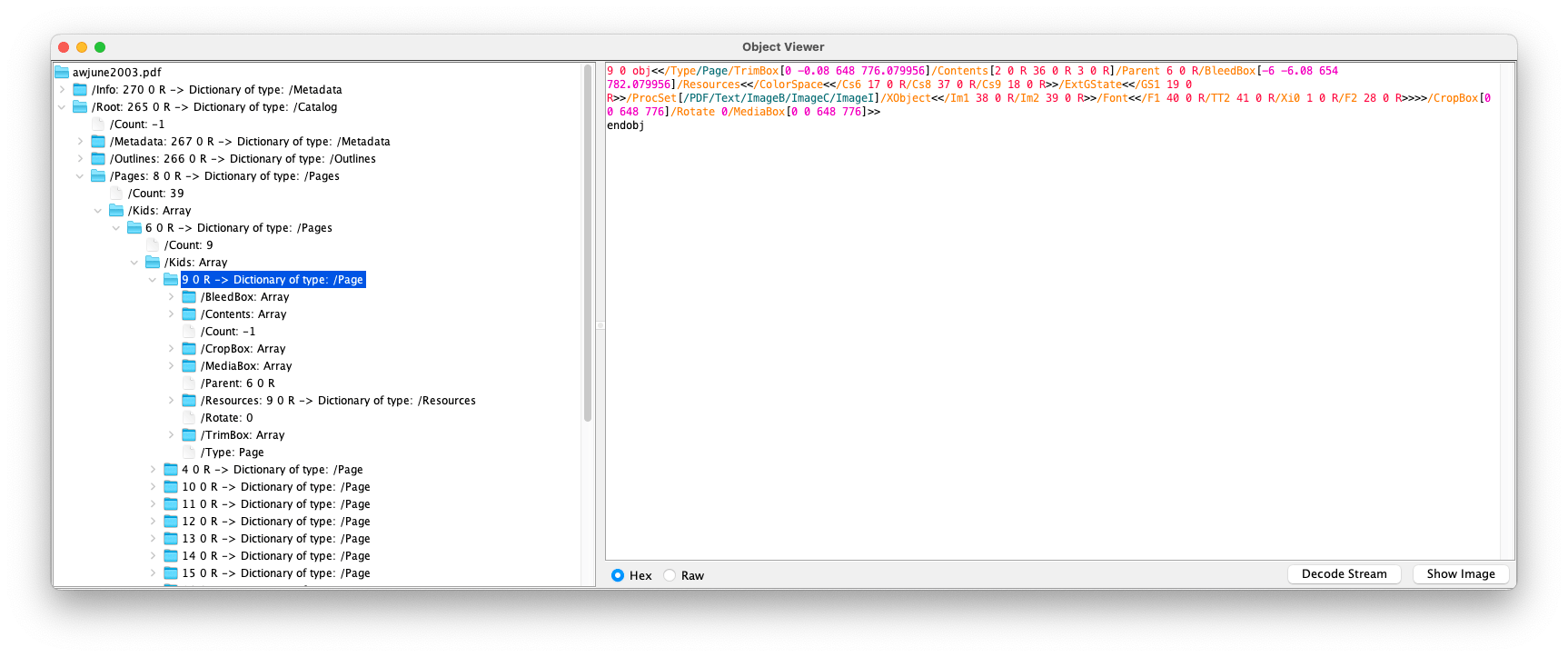
Cross-Reference Table
The cross-reference table enumerates all of the objects within the file, and their locations in the form of a byte offset. The benefit of knowing each object’s byte offset is that it allows random access to the file which can significantly improve performance. You therefor do not need to read the entire file to display a single page.
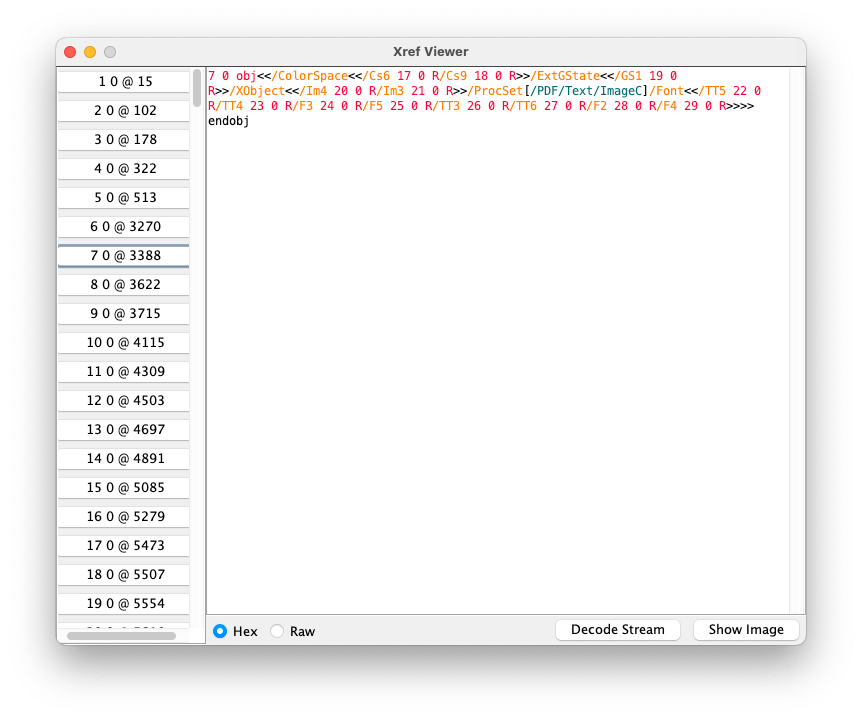
Trailer
PDF files are typically read starting at the end, which is where the file trailer resides. It contains the root object, some metadata, and most importantly, the byte offset of the cross-reference table.
It is a dictionary denoted by the trailer keyword. The end of a PDF file should always be %%EOF.
Text
Text in a PDF file is stored in the /Contents stream object. Many different commands (Tj, Tf, TD, Tw, and more) are used to position and draw the text on the page. Learn more.

Images
Images are stored in XObjects, which are just stream objects that contain the raw binary image data. They are not stored in any format like PNG, JPEG. Rather, they are stored as the binary data for the pixels, and the colorspace information. This is often compressed using one or more filters. Learn more.
JPedal Inspector
This article was created using the JPedal Inspector, which developers use for PDF debugging and to analyse the inner workings of PDF files. It has various features such as a COS tree viewer, XREF table viewer, and a stream debugger complete with breakpoints. You can learn more about JPedal or check out this tutorial on how to use the Inspector. JPedal is the best Java PDF library for developers.
By understanding the PDF file structure, developers can efficiently manipulate, render, and debug PDF documents. We also have other articles to help you better understand the PDF file format.
The JPedal PDF library allows you to solve these problems in Java
//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
final PdfManipulator pdf = new PdfManipulator();
pdf.loadDocument(new File("inputFile.pdf"));
pdf.addPage(1, PaperSize.A4_LANDSCAPE);
pdf.addText(1, "Hello World", 10, 10, BaseFont.HelveticaBold, 12, 1, 0.3f, 0.2f);
pdf.addImage(1, new BufferedImage(), new float[] {0, 0, 100, 100});
pdf.rotatePage(1, 90);
pdf.apply();
pdf.writeDocument(new File("outputFile.pdf"));Viewer viewer = new Viewer();
viewer.setupViewer();
viewer.executeCommand(ViewerCommands.OPENFILE, "pdfFile.pdf");
//Convenience static method (see class for additional options)
ExtractTextAsWordList.writeAllWordlistsToDir("inputFileOrDirectory", "outputDir", -1);
PdfMerge.mergeFiles(new File("inputFile1.pdf"), new File("inputFile2.pdf"), new File("outputFile.pdf"));
PdfManipulator.splitInHalf(new File("inputFile.pdf"), new File("outputFolder"), pageToSplitAt);PrintPdfPages print = new PrintPdfPages("C:/pdfs/mypdf.pdf");
if (print.openPDFFile()) {
print.printAllPages("Printer Name");
}//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
//Convenience static method (see class for additional options)
ArrayList resultsForPages = FindTextInRectangle.findTextOnAllPages("/path/to/file.pdf", "textToFind");
java -jar jpedal.jar --inspect "inputFile.pdf"PdfSigner.signPdf(
"inputFile.pdf",
"outputFile.pdf",
"keystorePassword",
"keystoreFile.p12",
"signerName",
"signerLocation",
"signingReason",
ACCESS_PERMISSION.P1
);What is JPedal?
JPedal is a commercial Java PDF Library that makes it easy for Java developers to work with PDF Documents in Java.
Why use JPedal?
JPedal makes it much easier to work with PDF files from Java. Because we have been actively developing our Java PDF Toolkit for over 20 years, it works with all those problem PDF files out there.
What licenses are available?
We have 2 licenses available:
'Server' for on premises and cloud servers and 'OEM' for use in a named end user applications. Both are one time fees with options support renewal after 12 months.
How to use JPedal?
Want to learn more about JPedal and how to use it, we have plenty of tutorials and guides to help you.