I was recently sent a PDF file where some of the metadata appeared to be wrong. In particular, the PRODUCER field was appearing in Chinese.
 Oh dear, I thought (or slightly less poetic words to that effect), and opened the file in Acrobat to see where I had gone wrong. That is where it became interesting, because this is what Acrobat 9.0 showed.
Oh dear, I thought (or slightly less poetic words to that effect), and opened the file in Acrobat to see where I had gone wrong. That is where it became interesting, because this is what Acrobat 9.0 showed.
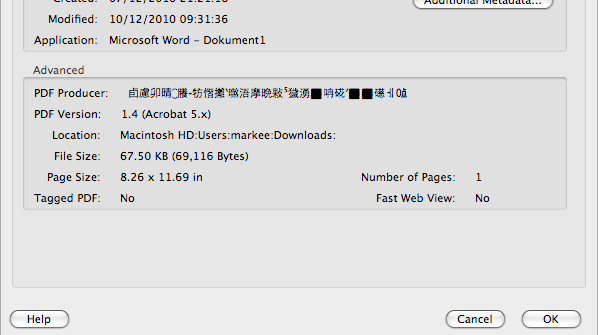 But some versions of Acrobat and Foxit actually show the PRODUCER as ScanSoft PDF Create! 5; modified using iText 2.1.7 by 1T3XT . So we have a bit of a mystery here…
But some versions of Acrobat and Foxit actually show the PRODUCER as ScanSoft PDF Create! 5; modified using iText 2.1.7 by 1T3XT . So we have a bit of a mystery here…
I opened up the PDF file in a text editor to look at the data and here is the PDF information object
20 0 obj<<
/CreationDate(D:20101207222118+01’00’)
/Title<feff004d006900630072006f0073006f0066007400200057006f007200640020002
d00200044006f006b0075006d0065006e00740031>
/Producer(˛ˇScanSoft PDF Create! 5; modified using iText 2.1.7 by 1T3XT)
/Author<feff006d0067>
/Creator<feff004d006900630072006f0073006f0066007400200057006f00720064002000
2d00200044006f006b0075006d0065006e00740031>
/ModDate(D:20101210103136+01’00’)
>>endobj
The Producer value is between 2 brackets and although it looks like a text string, it is in fact a binary values which can be encoded either as 2 byte unicode or as PDFDocEncoding (essentially ASCII so it actually looks like text in a viewer). The key to the mystery here is the 2 funny characters at the start ˛ˇ which are actually byte values 254 and 255. This indicates that the rest of the data is 2 byte Unicode. As you can see this is not the case.
So the problem is that the string is wrongly encoded. Some tools are either assuming it must be PDFDocEncoding (so getting it right in this case) or have their own strategy for spotting the mistake.
There are quite a few cases where PDF files can deviate from the Spec, such as the All TrueType Fonts are MAC encoded (unless they are not), issue I wrote about in another post.
Have you found any oddities in your PDF files?
Our software libraries allow you to
| Convert PDF files to HTML |
| Use PDF Forms in a web browser |
| Convert PDF Documents to an image |
| Work with PDF Documents in Java |
| Read and write HEIC and other Image formats in Java |
I have exactly the same problem with iText 2.1.7.
Have you found a work-around for this without changing the iText sources?
Sorry. I think you need to upgrade
I know this is from years ago. We have iText 5.x and some users get chinese characters everywhere in their pdf when they open it in notepad on Windows. Any recommendations? Upgrading to iText 7 isn’t an option as that would take a good week or two to change all our code that uses iText.
I tis perfectly valid to do this in PDF spec. Your best bet would be to read the Producer via iText rather than open it in a text editor.
Thanks Mark. Understood. But it isn’t me opening it, it is a PDF that our clients will submit to a US Court official and that is their practice to first open it in Notepad and search for a text string, and then they have some application that reads in some xml that we had to put in a non-standard location in the metadata of the PDF. They are not technical and reading it in Notepad for a specific reason for them. The odd thing is that it is not all the PDFs that end up like this, we have a Spring Web App, the REST call comes in to run a Jasper Report, then we take the report PDF, still in the REST call, open it with iText, add the xml to the xmp metadata section, then set it to be PDF/A then send it to the browser as either a preview in the browser or direct download to the users machine. They then (not technical people) send it to the US Courts via email, and someone there opens it in Notepad to see if they can find a String in that XML and if they do, they then send it to another office at the courts where they plug it into some special program they use to extract out the XML. So I have no control over their process and rejecting the files, and then the clients really complain to us and we lose their business. Which is tough since our entire pool of potential clients is only 1100 people. Sorry for the long winded response. But thanks for this post too, it is amazing how you can post something a long time ago and it still has tremendous value years later.
Have you tried reading and rewriting it with another version of Text or other tool to fix it?
We have iText 5 latest version of 5. It would take us weeks to upgrade to iText 7 besides how much testing we would need to do before we could deploy that. I don’t think the upgrade would do anything to change our results. It also seems to only happen on Windows machines as it has never happened to a few of us that have Macs. What other tools can add data to XMP as well as convert it to PDF/A that is as good or better than iText. I don’t think PDFBox has all those features. Thanks.