
This tutorial shows you how to extract text from a PDF file in simple steps using JPedal Java PDF library. JPedal is the best Java PDF library for developers. It covers different formats of text and the Java code to extract it these variations.
How to extract Unstructured Text from a PDF file
- Download JPedal trial jar.
- Create a File handle, InputStream or URL pointing to the PDF file
- Include a password if file password protected
- Open the PDF file
- Iterate over the pages to extract the text
- Close the PDF file
and the Java code to extract Unstructured text from PDF…
ExtractTextInRectangle extract=new ExtractTextInRectangle("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
int pageCount=extract.getPageCount();
for (int page=1; page<=pageCount; page++) {
String text=extract.getTextOnPage(page);
}
}
extract.closePDFfile();
Below is an example of original PDF vs extracted unstructured text:
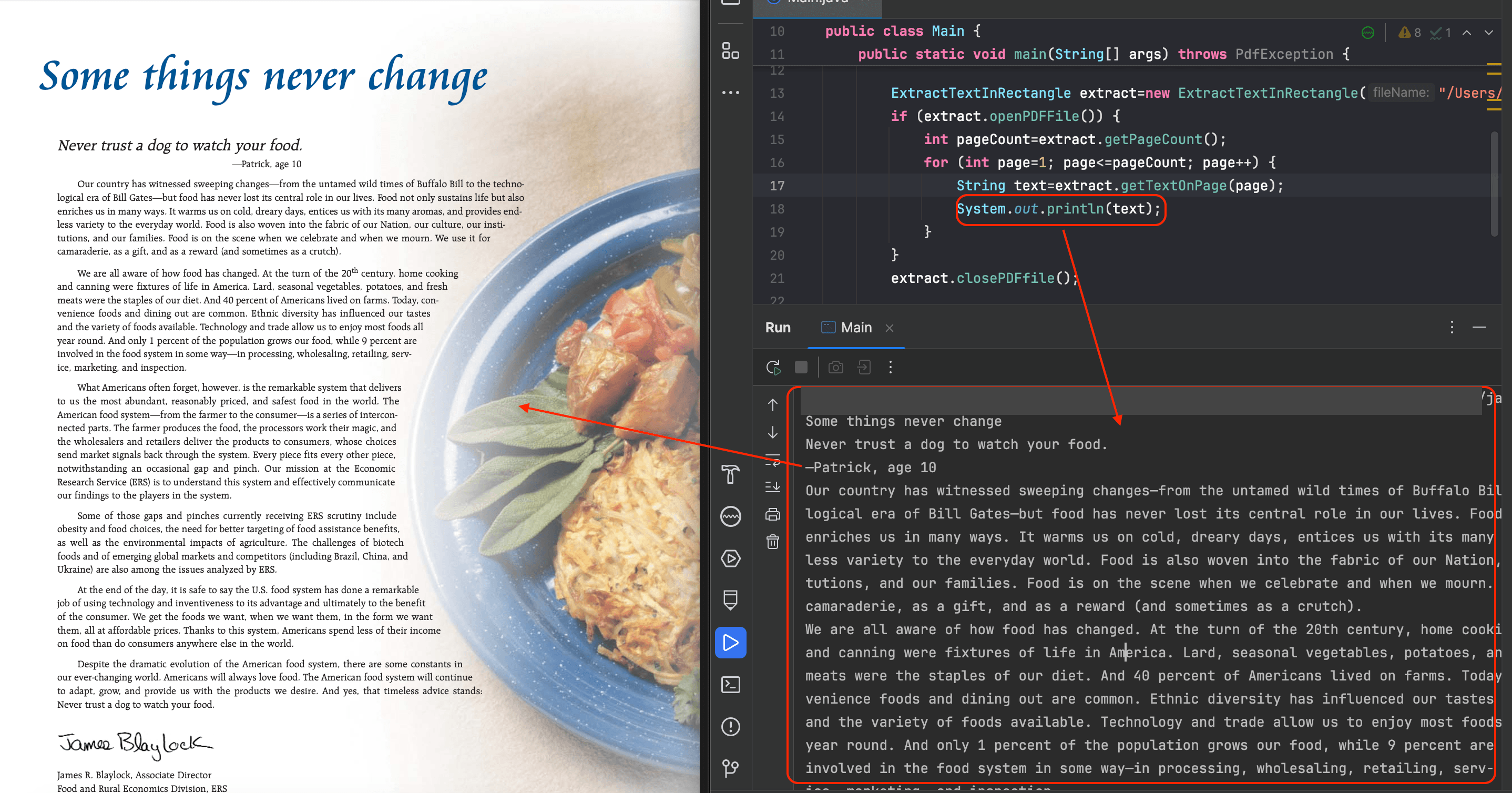
How to extract Structured Text from a tagged PDF file
- Download JPedal trial jar.
- Choose output format
- Create a File handle, InputStream or URL pointing to the PDF file
- Include a password if file password protected
- Open the PDF file
- Extract the Document text
- Close the PDF file
Java code to extract Structured Text…
ExtractStructuredTextProperties properties = new ExtractStructuredTextProperties();
properties.setFileOutputMode(OutputModes.XML);
//properties.setFileOutputMode(OutputModes.HTML);
ExtractStructuredText extract = new ExtractStructuredText("C:/pdfs/mypdf.pdf", properties);
//extract.setPassword("password");
if (extract.openPDFFile()) {
Document anyStructuredText = extract.getStructuredTextContent();
}
extract.closePDFfile();
For demonstration purpose, I’ve added a simple check to see if structured texts exist in my sample PDF.
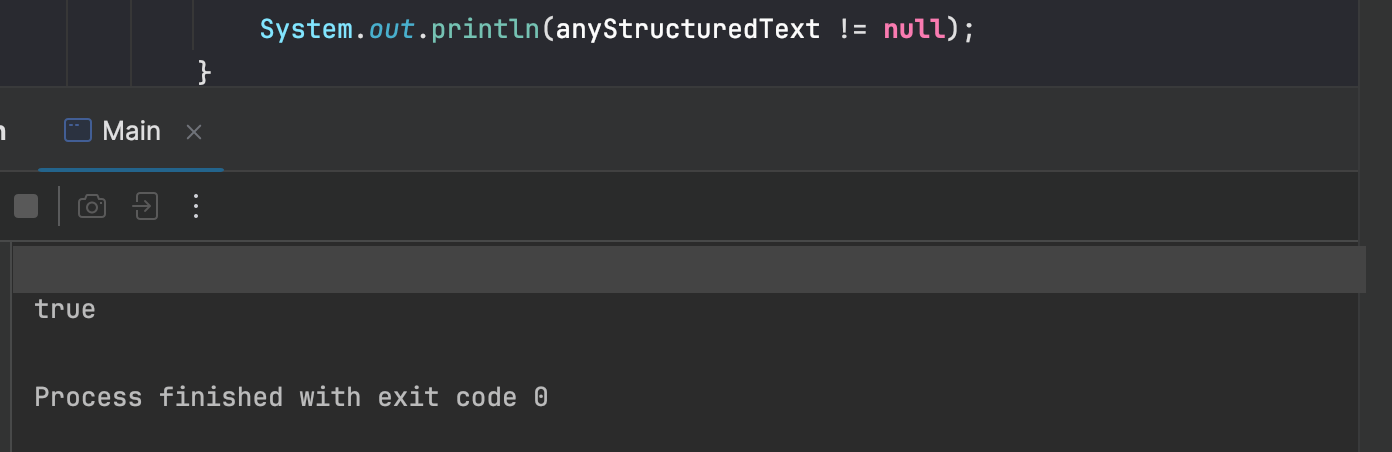
How to extract Wordlist from a PDF file
- Download JPedal trial jar.
- Create a File handle, InputStream or URL pointing to the PDF file
- Include a password if file password protected
- Open the PDF file
- Iterate over the pages to extract the text
- Close the PDF file
and the Java code to extract a wordlist text from PDF…
ExtractTextAsWordlist extract = new ExtractTextAsWordlist("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
int pageCount=extract.getPageCount();
for (int page=1; page<=pageCount; page++) {
List wordList=extract.getWordsOnPage(page);
}
}
extract.closePDFfile();
Below is an example of original PDF vs extracted wordlist:
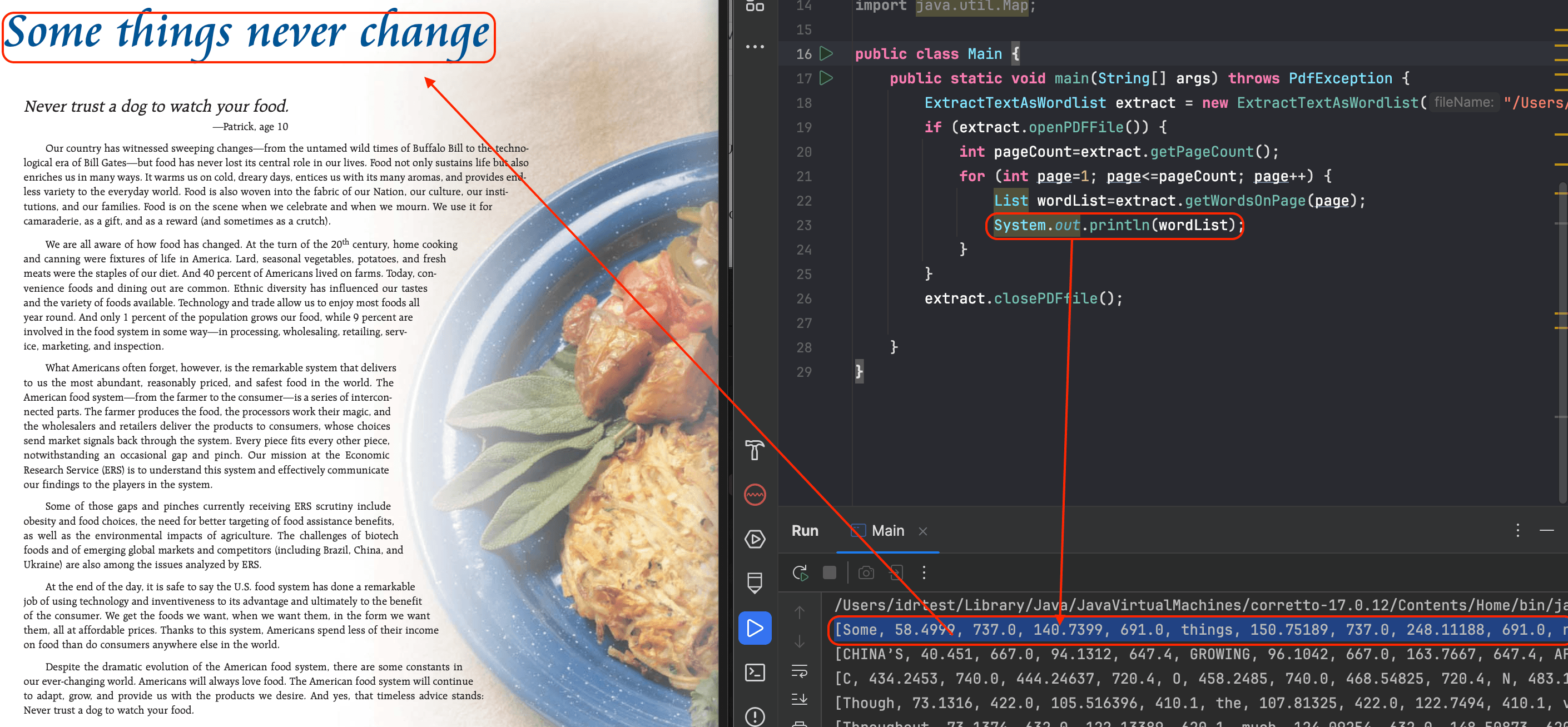
How to extract Document outline from PDF files
- Download JPedal trial jar.
- Create a File handle, InputStream or URL pointing to the PDF file
- Include a password if file password protected
- Open the PDF file
- Extract the document outline
- Close the PDF file
and the Java code to extract a Document outline from PDF…
ExtractOutline extract=new ExtractOutline("C:/pdfs/mypdf.pdf");
//extract.setPassword("password");
if (extract.openPDFFile()) {
Document pdfOutline=extract.getPDFTextOutline();
}
extract.closePDFfile();
For demonstration purpose, I’ve added a simple check to see if the outline has been extracted from my sample PDF.
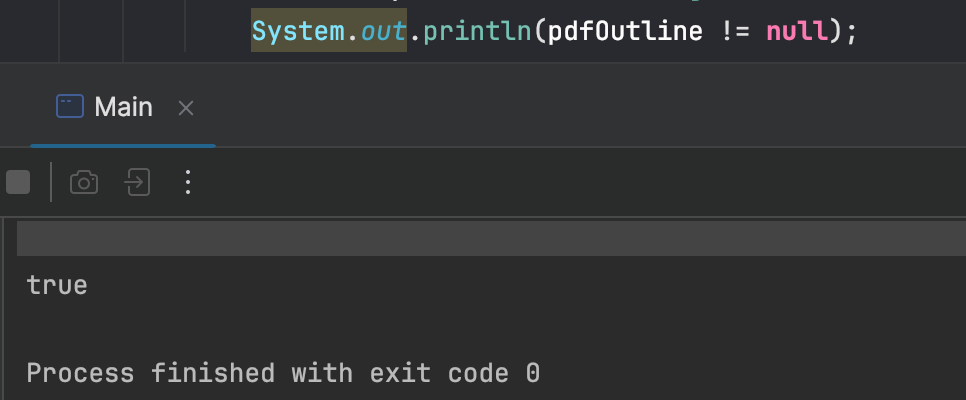
The JPedal PDF library allows you to solve these problems in Java
//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
final PdfManipulator pdf = new PdfManipulator();
pdf.loadDocument(new File("inputFile.pdf"));
pdf.addPage(1, PaperSize.A4_LANDSCAPE);
pdf.addText(1, "Hello World", 10, 10, BaseFont.HelveticaBold, 12, 1, 0.3f, 0.2f);
pdf.addImage(1, new BufferedImage(), new float[] {0, 0, 100, 100});
pdf.rotatePage(1, 90);
pdf.apply();
pdf.writeDocument(new File("outputFile.pdf"));Viewer viewer = new Viewer();
viewer.setupViewer();
viewer.executeCommand(ViewerCommands.OPENFILE, "pdfFile.pdf");
//Convenience static method (see class for additional options)
ExtractTextAsWordList.writeAllWordlistsToDir("inputFileOrDirectory", "outputDir", -1);
PdfMerge.mergeFiles(new File("inputFile1.pdf"), new File("inputFile2.pdf"), new File("outputFile.pdf"));
PdfManipulator.splitInHalf(new File("inputFile.pdf"), new File("outputFolder"), pageToSplitAt);PrintPdfPages print = new PrintPdfPages("C:/pdfs/mypdf.pdf");
if (print.openPDFFile()) {
print.printAllPages("Printer Name");
}//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
//Convenience static method (see class for additional options)
ArrayList resultsForPages = FindTextInRectangle.findTextOnAllPages("/path/to/file.pdf", "textToFind");
java -jar jpedal.jar --inspect "inputFile.pdf"PdfSigner.signPdf(
"inputFile.pdf",
"outputFile.pdf",
"keystorePassword",
"keystoreFile.p12",
"signerName",
"signerLocation",
"signingReason",
ACCESS_PERMISSION.P1
);What is JPedal?
JPedal is a commercial Java PDF Library that makes it easy for Java developers to work with PDF Documents in Java.
Why use JPedal?
JPedal makes it much easier to work with PDF files from Java. Because we have been actively developing our Java PDF Toolkit for over 20 years, it works with all those problem PDF files out there.
What licenses are available?
We have 2 licenses available:
'Server' for on premises and cloud servers and 'OEM' for use in a named end user applications. Both are one time fees with options support renewal after 12 months.
How to use JPedal?
Want to learn more about JPedal and how to use it, we have plenty of tutorials and guides to help you.