TL;DR
True PDF redaction in Java requires two things: hiding the text visually and removing it from the content stream. This tutorial shows how to do both with JPedal in under 20 lines of code.

Why remove text from a PDF file?
Removing text from a PDF in Java is a common requirement when dealing with sensitive information, names, email addresses, phone numbers, and other personally identifiable information. Whether you are meeting GDPR redaction obligations, preparing documents for external sharing, or sanitising files before archiving, this tutorial explains how to do it using the JPedal PDF library.
What redaction actually means
Removing text from a PDF is a two-part problem. First, you find the text. Then you redact it, which itself has two layers:
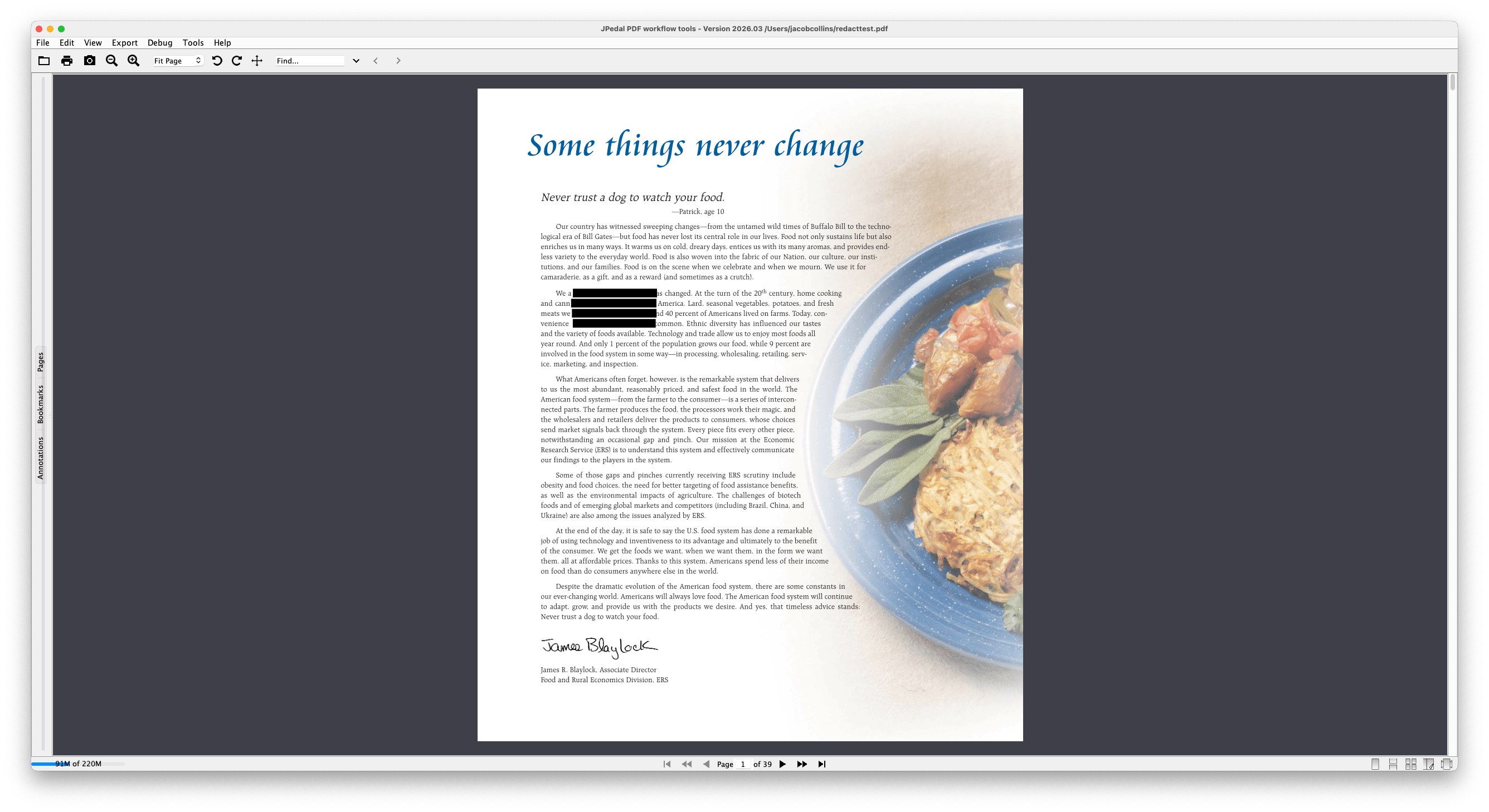
- Hide the text visually, usually done by drawing an opaque box over it
- Remove it from the underlying content stream so it cannot be extracted by a PDF reader or copy-paste
Both steps are critical. Drawing a black box without editing the content stream is not true redaction. The text is still there, just invisible, and people will be able to copy and paste it. JPedal handles both steps, and together these are called redaction.
Choosing a Java PDF library for text removal
Most developers reach for Apache PDFBox first, but programmatically removing text from a PDF in Java, rather than just drawing over it, requires direct access to the content stream. JPedal exposes this through a clean API, handling both the search and the redaction in a few lines of code without manual stream manipulation.
Find, delete and redact text from a PDF in Java using JPedal
Open the PDF, scan each page for the target text, redact every match, then write out the modified document. The key methods are findTextOnPage() to locate matches and redact() to remove them. pdf.apply() commits the redaction operations to the document before writing.
- Download JPedal trial jar.
- Create a File handle to the PDF file
- Include a password if file password protected
- Open the PDF file
- Scan the pages for text
- Redact each match
- Write the output and close
final File inputFile = new File("inputFile.pdf");
final FindTextInRectangle extract = new FindTextInRectangle(inputFile);
final PdfManipulator pdf = new PdfManipulator();
pdf.loadDocument(inputFile);
if (extract.openPDFFile()) {
final int pageCount = extract.getPageCount();
for (int page = 1; page <= pageCount; page++) {
final float[] coords = extract.findTextOnPage(page, "the", SearchType.MUTLI_LINE_RESULTS);
for (int val = 0; val < coords.length; val = val + 5) {
pdf.redact(page, new float[] {coords[val], coords[val + 1], coords[val + 2], coords[val + 3]});
}
}
}
extract.closePDFfile();
//apply changes and write out
pdf.apply();
final File outputFile = new File("redactedFile.pdf");
pdf.writeDocument(outputFile);
pdf.closeDocument();
findTextOnPage() returns a flat float array of coordinates for each match, x1, y1, x2, y2, plus a fifth value (magic number documented here) at index 4, which is why the loop increments by 5. The output is a new PDF with every instance of the search term permanently removed from both the visual layer and the content stream.The original file is not modified unless you overwrite it. Add try-catch blocks around the file operations and PDF calls for production use. For other PDF text manipulation tasks in Java, extracting, searching, or modifying content programmatically, see the JPedal tutorials.
You can expand your understanding of the PDF format by reading our other articles. Similarly, if there is a specific term for PDF you would like to know more about, our PDF Glossary has an extensive list of common terms.
The JPedal PDF library allows you to solve these problems in Java
//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
final PdfManipulator pdf = new PdfManipulator();
pdf.loadDocument(new File("inputFile.pdf"));
pdf.addPage(1, PaperSize.A4_LANDSCAPE);
pdf.addText(1, "Hello World", 10, 10, BaseFont.HelveticaBold, 12, 1, 0.3f, 0.2f);
pdf.addImage(1, new BufferedImage(), new float[] {0, 0, 100, 100});
pdf.rotatePage(1, 90);
pdf.apply();
pdf.writeDocument(new File("outputFile.pdf"));Viewer viewer = new Viewer();
viewer.setupViewer();
viewer.executeCommand(ViewerCommands.OPENFILE, "pdfFile.pdf");
//Convenience static method (see class for additional options)
ExtractTextAsWordList.writeAllWordlistsToDir("inputFileOrDirectory", "outputDir", -1);
PdfMerge.mergeFiles(new File("inputFile1.pdf"), new File("inputFile2.pdf"), new File("outputFile.pdf"));
PdfManipulator.splitInHalf(new File("inputFile.pdf"), new File("outputFolder"), pageToSplitAt);PrintPdfPages print = new PrintPdfPages("C:/pdfs/mypdf.pdf");
if (print.openPDFFile()) {
print.printAllPages("Printer Name");
}//Convenience static method (see class for additional options)
ExtractClippedImages.writeAllClippedImagesToDir("inputFileOrDirectory", "outputDir", "outputImageFormat", new String[] {"imageHeightAsFloat", "subDirectoryForHeight"});
//Convenience static method (see class for additional options)
ArrayList resultsForPages = FindTextInRectangle.findTextOnAllPages("/path/to/file.pdf", "textToFind");
java -jar jpedal.jar --inspect "inputFile.pdf"PdfSigner.signPdf(
"inputFile.pdf",
"outputFile.pdf",
"keystorePassword",
"keystoreFile.p12",
"signerName",
"signerLocation",
"signingReason",
ACCESS_PERMISSION.P1
);What is JPedal?
JPedal is a commercial Java PDF Library that makes it easy for Java developers to work with PDF Documents in Java.
Why use JPedal?
JPedal makes it much easier to work with PDF files from Java. Because we have been actively developing our Java PDF Toolkit for over 20 years, it works with all those problem PDF files out there.
What licenses are available?
We have 2 licenses available:
'Server' for on premises and cloud servers and 'OEM' for use in a named end user applications. Both are one time fees with options support renewal after 12 months.
How to use JPedal?
Want to learn more about JPedal and how to use it, we have plenty of tutorials and guides to help you.