Introduction
XFA data exists in a different format to normal PDF data. This article is designed to help you understand how this happens and how you can make sue of this. At the end I will link to a tutorial showing how we allow users to access this data in our commercial Java software library.
What is XFA?
XFA is a way of describing both dynamic form content and static pages using an XML mark-up language. It was invented by a company called JefForm which was acquired by Adobe. The idea was to replace the old AcroForm technology with a new XML based format and a new Forms Application (LiveCycle) to edit and create it. It is now heavily used by many government and corporate organisations who have a significant investment in Adobe technology.
XFA support
Because XFA is a very complex add-in for PDF (and is not in the PDF specification), most tools do not support it. You will see a screen telling you that you need to upgrade to the latest version of Adobe Acrobat. The only tools I am aware of with good XFA support are Adobe’s toolset, Fixit, IText and our JPedal PDF library.
Getting at the XFA data inside the PDF file
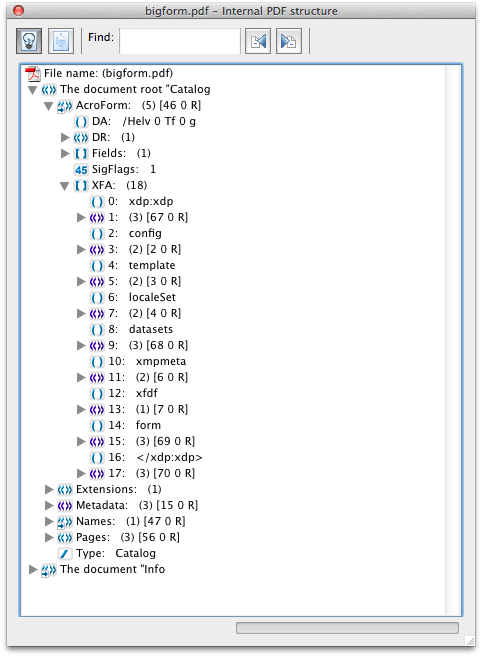
XFA is stored as a set of XML streams inside traditional PDF Objects (so they can be encrypted and compressed). So reading it really needs a PDF library which can access and decode PDF objects for you. Unlike Annotations (which are defined on a page level), they are defined at the document level. Each XML stream is in its own PDF object. inside the Acroforms XFA entry.
The layout of the forms and pages (template) is separate from the actual dataset (which can also define several items you might think of as part of the layout such as the number rows). So if you only need to access or edit the form data, you just need to access the dataset.
This is what it looks like in a sample PDF file, using the Acrobat object viewer.
Is the XFA self-contained?
No. It can also access data in other PDF objects (for example image data or Signature details).
Where can I learn more?
If you want to learn more about XFA, there is a wiki post on XFA and we have lots of XFA articles on our blog. See how do we access the PDF data in our PDF library here.
FormVu allows you to
| Use Interactive PDF Forms in the Web Browser |
| Integrate fillable PDF Forms into Web Apps |
| Parse PDF forms as HTML5 |
What is FormVu?
FormVu is a commercial SDK for converting PDF Form files into standalone HTML with interactive form components.
Why use FormVu?
FormVu allows you to integrate PDF forms into your web application effortlessly while retaining all their interaction and functionality.
What licenses are available?
We have 3 licenses available:
Cloud for form conversion using the shared IDRsolutions cloud server, Self hosted server option for your own cloud or on-premise servers, and Enterprise for more demanding requirements.
How to use FormVu?
Want to learn more about FormVu and how to use it, we have plenty of tutorials and guides to help you.