Introduction
Text works differently in PDFs and in HTML files, which can make it a surprisingly complex problem to get great output during PDF to HTML5 conversion.
Understanding PDF Text Structure
PDF text is actually two entirely separate values – a value for choosing what glyph to display (display value), and a value for extraction (extraction value). You might find that a title appears entirely in capitals, but when you copy the text and paste it elsewhere it’s all lower case.
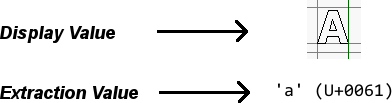
Common Problems with PDF Text
When Extraction Values Are Incorrect
Slightly less usefully, you sometimes find PDF files which, when you copy the text out, is complete gibberish. The extraction values might be completely wrong, but because the display values are correct it looks right in Adobe Reader.
When Glyphs Are Mislabelled
Equally, you sometimes find that the extraction values are fine, but if you open up the font you see that the glyphs are completely mislabelled, so typing ‘U’ could make a ‘!’ appear. Again, it will look right in Adobe Reader if the display values match the wrong values in the font.
How HTML Handles Text
HTML treats text much more simply – there’s no concept of separating the display and extraction values, so what you see is what you get.
Choosing Which Value to Use
So, when you’re converting from PDF text to HTML5 output, which value should you use?
It’s a trick question – neither.
If you use the display value, it should look right, but there’s a pretty high chance the text will be completely wrong when you copy it out of the PDF. Amongst other things, that means search engines can’t understand your content and one of the benefits of having HTML documents is lost.
If you use the extraction value, there’s no guarantee that it will map onto the right glyph in the font, or that it will map onto any value in the font. Even if you rewrote the font to get the values to match, you could have the same extraction values being used for multiple different glyphs, which could make for some ugly problems.
One file I’ve seen uses the extraction value ‘h’ for bullet points – if we used that mapping, you could see bullet points popping up in the middle of words.
The BuildVu Solution
So what we actually do now with BuildVu is that we use a potentially modified version of the extraction value. If an extraction value has already been used to show a different glyph before, we use a different value.
We build up a map of these values and rewrite the font to map them onto the right glyph. This gives us a good shot at preserving all of the content in the file whilst also making sure that the text looks right.

This is just one of the many improvements we’ve been making to our output, with many more – including improving our Type 1 support – on the way.
BuildVu allows you to
| View PDF files in a Web app |
| Convert PDF documents to HTML5 |
| Parse PDF documents as HTML |
What is BuildVu?
BuildVu is a commercial SDK for converting PDF files into standalone HTML or SVG.
Why use BuildVu?
BuildVu allows you to integrate PDF into your HTML workflow effortlessly and securely by producing clean HTML that is easy for developers to work with.
What licenses are available?
We have 3 licenses available:
Cloud for conversion using the shared IDRsolutions cloud server, Self hosted server option for your own cloud or on-premise servers, and Enterprise for more demanding requirements.
How to use BuildVu?
Want to learn more about BuildVu and how to use it, we have plenty of tutorials and guides to help you.
Wow. Very interesting. I think that is a great solution.